你的位置:上海证券期货公司-股票期货平台-线上期货交易 > 上海证券期货公司 > 股票质押信托 4090笔记本0.37秒直出大片!英伟达联手MIT清华祭出Sana架构


炸洋芋、烤乳扇、菌子火锅、米线、舂鸡脚、包浆豆腐、鲜花饼……细数剧中的云南当地特色美食股票质押信托,那可真是花样繁多。
在琳琅满目的冷冻食品货架上,冷冻虾仁以其多样化的品牌和包装吸引着消费者的目光。然而,在这背后,却隐藏着品质参差不齐、来源不明等隐忧。随着市场需求的激增,一些不良商家为了降低成本,不惜以次充好,使用不新鲜的原料或不当的保存方式,导致消费者在购买时难以辨别,吃到有质量保证的冷冻虾仁变得愈发困难。因此,选择可信赖的品牌,关注产品的产地、生产日期及保存方式,成为了每一位美食爱好者必须掌握的技巧。
编辑:桃子 好困
【新智元导读】一台4090笔记本,秒生1K质量高清图。英伟达联合MIT清华团队提出的Sana架构,得益于核心架构创新,具备了惊人的图像生成速度,而且最高能实现4k分辨率。
一台16GB的4090笔记本,仅需0.37秒,直接吐出1024×1024像素图片。

如此神速AI生图工具,竟是出自英伟达MIT清华全华人团队之笔!
正如其名字一样,Sana能以惊人速度合成高分辨率、高质量,且具有强文本-图像对其能力的模型。
而且,它还能高效生成高达4096×4096像素的图像。

项目主页:https://nvlabs.github.io/Sana/
论文地址:https://arxiv.org/abs/2410.10629
Sana的核心设计包含了以下几个要素:
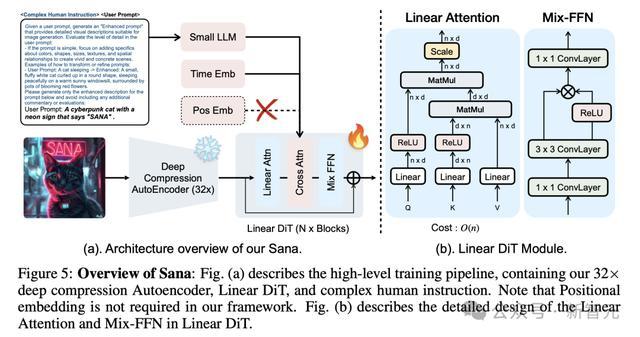
深度压缩自编码器(AE):传统自编码器只能将图像压缩8倍,全新AE可将图像压缩32倍,有效减少了潜在token的数量。
线性DiT(Diffusion Transformer):用「线性注意力」替换了DiT中所有的普通注意力,在高分辨率下更加高效,且不会牺牲质量。
基于仅解码器模型的文本编码器:用现代的仅解码器SLM替换T5作为文本编码器,并设计了复杂的人类指令,通过上下文学习来增强图像-文本对齐。
高效的训练和采样:提出Flow-DPM-Solver来减少采样步骤,并通过高效的标题标注和选择来加速收敛。
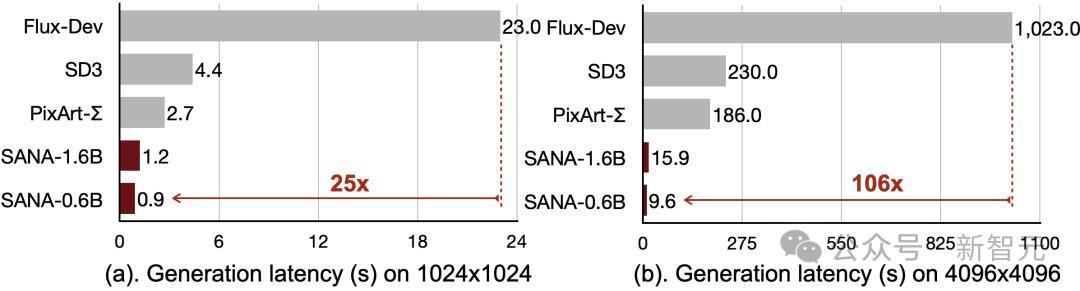
基于以上的算法创新,相较于领先扩散模型Flux-12B,Sana-0.6B不仅参数小12倍,重要的是吞吐量飙升100倍。
以后,低成本的内容创作,Sana才堪称这一领域的王者。
效果一览
一只赛博猫,和一个带有「SANA」字样的霓虹灯牌。

一位站在山顶上的巫师,在夜空中施展魔法,形成了由彩色能量组成的「NV」字样。

在人物的生成方面,Sana对小女孩面部的描绘可以说是非常地细致了。

下面来看个更复杂的:
一艘海盗船被困在宇宙漩涡星云中,通过模拟宇宙海滩旋涡的特效引擎渲染,呈现出令人惊叹的立体光效。场景中弥漫着壮丽的环境光和光污染,营造出电影般的氛围。整幅作品采用新艺术风格,由艺术家SenseiJaye创作的插画艺术,充满精致细节。

甚至,像下面这种超级复杂的提示,Sana也能get到其中的关键信息,并生成相应的元素和风格。
Prompt:a stunning and luxurious bedroom carved into a rocky mountainside seamlessly blending nature with modern design with a plush earth-toned bed textured stone walls circular fireplace massive uniquely shaped window framing snow-capped mountains dense forests, tranquil mountain retreat offering breathtaking views of alpine landscape wooden floors soft rugs rustic sophisticated charm, cozy tranquil peaceful relaxing perfect escape unwind connect with nature, soothing intimate elegance modern design raw beauty of nature harmonious blend captivating view enchanting inviting space, soft ambient lighting warm hues indirect lighting natural daylight balanced inviting glow

顺便,团队还给经典梗图,生成了一个卡通版变体(右)。

设计细节
Sana的核心组件,已在开头简要给出介绍。接下来,将更进一步展开它们实现的细节。
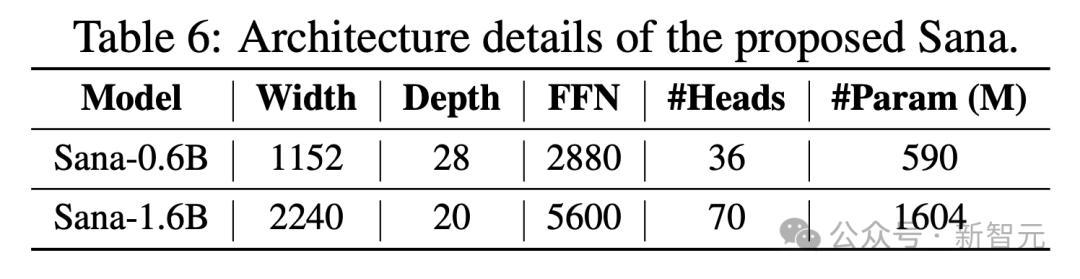
模型架构的细节,如下表所示。
- 深度压缩自编码器
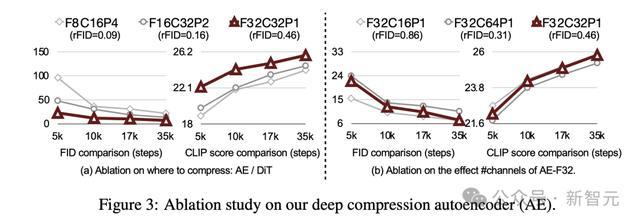
研究人员引入的全新自编码器(AE),大幅将缩放因子提高至32倍。
过去,主流的AE将图像的长度和宽度,只能压缩8倍(AE-F8)。
与AE-F8相比,AE-F32输出的潜在token数量减少了16倍,这对于高效训练和生成超高分辨率图像(如4K分辨率)至关重要。
- 高效线性DiT(Diffusion Transformer)
原始DiT的自注意力计算复杂度为O(N²),在处理高分辨率图像时呈二次增长。
线性DiT在此替换了传统的二次注意力机制,将计算复杂度从O(N²)降低到O(N)。
与此同时,研究人员还提出了Mix-FFN,可以在多层感知器(MLP)中使用3×3深度卷积,增强了token的局部信息。
实验结果显示,线性注意力达到了与传统注意力相当的结果,在4K图像生成方面将延迟缩短了1.7倍。
此外,Mix-FFN无需位置编码(NoPE)就能保持生成质量,成为首个不使用位置嵌入的DiT。
- 基于仅解码器「小语言模型」的文本编码器
这里,研究人员使用了Gemma(仅解码器LLM)作为文本编码器,以增强对提示词的理解和推理能力。
尽管T2I生成模型多年来取得了显著进展,但大多数现有模型仍依赖CLIP或T5进行文本编码,这些模型往往缺乏强大的文本理解和指令跟随能力。
与CLIP或T5不同,Gemma提供了更优的文本理解和指令跟随能力,由此解训练了不稳定的问题。
他们还设计了复杂人类指令(CHI),来利用Gemma强大指令跟随、上下文学习和推理能力,改善了图像-文本对齐。

在速度相近的情况下,Gemma-2B模型比T5-large性能更好,与更大更慢的T5-XXL性能相当。
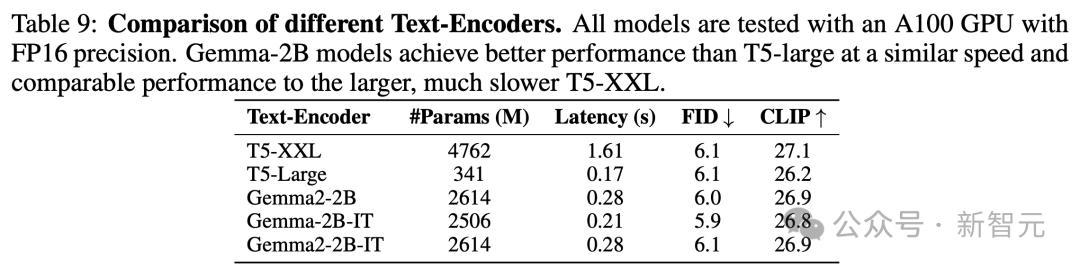
- 高效训练和推理策略
另外,研究人员还提出了一套自动标注和训练策略,以提高文本和图像之间的一致性。
首先,对于每张图像,利用多个视觉语言模型(VLM)生成重新描述。尽管这些VLM的能力各不相同,但它们的互补优势提高了描述的多样性。
此外,他们还提出了一种基于clipscore的训练策略,根据概率动态选择与图像对应的多个描述中具有高clip分数的描述。
实验表明,这种方法改善了训练收敛和文本-图像对齐能力。
此外,与广泛使用的Flow-Euler-Solver相比,团队提出的Flow-DPM-Solver将推理采样步骤从28-50步显著减少到14-20步,同时还能获得更优的结果。

整体性能
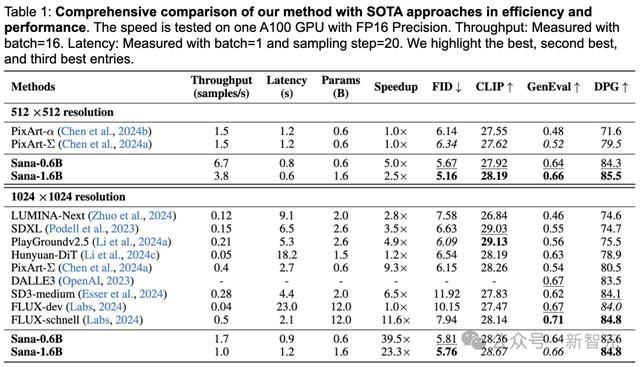
如下表1中,将Sana与当前最先进的文本生成图像扩散模型进行了比较。
对于512×512分辨率:- Sana-0.6的吞吐量比具有相似模型大小的PixArt-Σ快5倍- 在FID、Clip Score、GenEval和DPG-Bench等方面,Sana-0.6显著优于PixArt-Σ
对于1024×1024分辨率:- Sana比大多数参数量少于3B的模型性能强得多- 在推理延迟方面表现尤为出色
与最先进的大型模型FLUX-dev的比较:- 在DPG-Bench上,准确率相当- 在GenEval上,性能略低- 然而,Sana-0.6B的吞吐量快39倍,Sana-1.6B快23倍
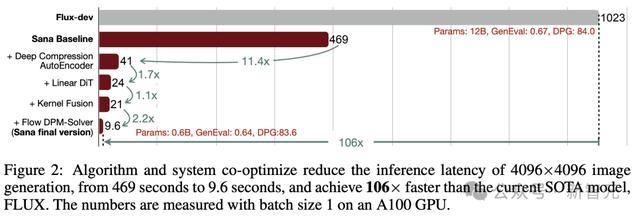
Sana-0.6吞吐量,要比当前最先进4096x4096图像生成方法Flux,快100倍。
而在1024×1024分辨率下,Sana的吞吐量要快40倍。
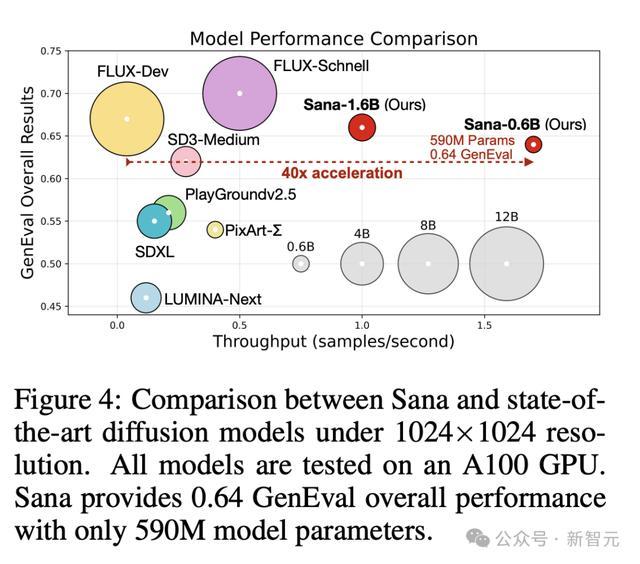
如下是,Sana-1.6B与其他模型可视化性能比较。很显然,Sana模型生成速度更快,质量更高。

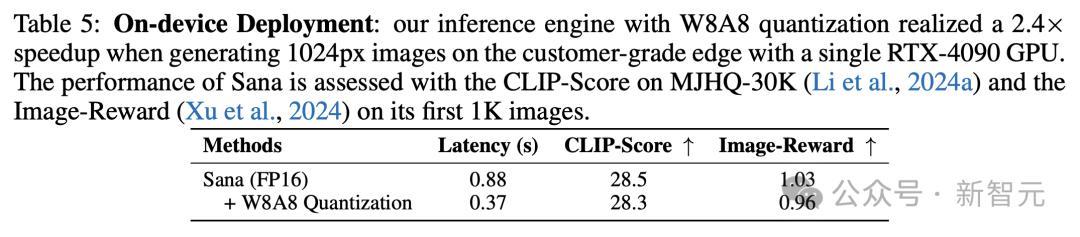
终端设备部署
为了增强边缘部署,研究人员使用8位整数对模型进行量化。
而且,他们还在CUDA C++中实现了W8A8 GEMM内核,并采用内核融合技术来减少不必要的激活加载和存储带来的开销,从而提高整体性能。
如下表5所示,研究人员在消费级4090上部署优化前后模型的结果比较。
在生成1024x1024图像方面,优化后模型实现了2.4倍加速,仅用0.37秒就生成了同等高质量图像。
作者介绍
Enze Xie(谢恩泽)

共同一作Enze Xie是NVIDIA Research的高级研究科学家,隶属于由麻省理工学院的Song Han教授领导的高效AI团队。此前,曾在华为诺亚方舟实验室(香港)AI理论实验室担任高级研究员和生成式AI研究主管。
他于2022年在香港大学计算机科学系获得博士学位,导师是Ping Luo教授,联合导师是Wenping Wang教授。并于朋友Wenhai Wang密切合作。
在攻读博士学习期间,他与阿德莱德大学的Chunhua Shen教授、加州理工学院的Anima Anandkumar教授以及多伦多大学的Sanja Fidler教授共事。同时,还与Facebook和NVIDIA等业界的多位研究人员进行了合作。
他的研究方向是高效的AIGC/LLM/VLM,并在实例级检测和自监督/半监督/弱监督学习领域做了一些工作——开发了多个CV领域非常知名的算法,以及一个2000多星的自监督学习框架OpenSelfSup(现名为mmselfsup)。
- PolarMask(CVPR 2020十大影响力论文排名第十)
- PVT(ICCV 2021十大影响力论文排名第二)
- SegFormer(NeurIPS 2021十大影响力论文排名第三)
- BEVFormer(ECCV 2022十大影响力论文排名第六)
Junsong Chen

共同一作Junsong Chen是NVIDIA Research的研究实习生,由Enze Xie博士和Song Han教授指导。同时,他也是大连理工大学IIAU实验室的博士生,导师是Huchuan Lu教授。
他的研究领域是生成式AI和机器学习的交叉,特别是深度学习及其应用的算法与系统协同设计。
此前,他曾在香港大学担任研究助理,由Ping Luo教授的指导。
Song Han(韩松)

Song Han是MIT电气工程与计算机科学系的副教授。此前,他在斯坦福大学获得博士学位。
他提出了包括剪枝和量化在内广泛用于高效AI计算的「深度压缩」技术,以及首次将权重稀疏性引入现代AI芯片的「高效推理引擎」——ISCA 50年历史上引用次数最多的前五篇论文之一。
他开创了TinyML研究,将深度学习引入物联网设备,实现边缘学习。
他的团队在硬件感知神经架构搜索方面的工作使用户能够设计、优化、缩小和部署 AI 模型到资源受限的硬件设备,在多个AI顶会的低功耗计算机视觉比赛中获得第一名。
最近,团队在大语言模型量化/加速(SmoothQuant、AWQ、StreamingLLM)方面的工作,有效提高了LLM推理的效率,并被NVIDIA TensorRT-LLM采用。
Song Han凭借着在「深度压缩」方面的贡献获得了ICLR和FPGA的最佳论文奖,并被MIT Technology Review评选为「35岁以下科技创新35人」。与此同时,他在「加速机器学习的高效算法和硬件」方面的研究,则获得了NSF CAREER奖、IEEE「AIs 10 to Watch: The Future of AI」奖和斯隆研究奖学金。
他是DeePhi(被AMD收购)的联合创始人,也是OmniML(被NVIDIA收购)的联合创始人。
参考资料:
https://nvlabs.github.io/Sana/
https://www.linkedin.com/feed/update/urn:li:activity:7251843706310275072/股票质押信托
Powered by 上海证券期货公司-股票期货平台-线上期货交易 @2013-2022 RSS地图 HTML地图